tcmalloc
系统内存管理
内存管理可以分为三个层次,自底向上分别是:
操作系统层级: 操作系统内核的内存管理
语言层级:glibc层使用系统调用维护的内存管理算法
应用层级:应用程序从glibc动态分配内存后,根据应用程序本身的程序特性进行优化, 比如使用引用计数std::shared_ptr,apache的内存池方式等等。当然应用程序也可以直接使用系统调用从内核分配内存,自己根据程序特性来维护内存,但是会大大增加开发成本。
tcmalloc介绍
tcmalloc是Google开源的一个内存管理库,常见的内存分配器还有glibc的ptmalloc和google的jemalloc。相比于ptmalloc,tcmalloc性能更好,特别适用于高并发场景。 作为glibc malloc的替代品。目前已经在chrome、safari等知名软件中运用。
根据官方测试报告,ptmalloc在一台2.8GHz的P4机器上(对于小对象)执行一次malloc及free大约需要300纳秒。而tcmalloc的版本同样的操作大约只需要50纳秒。
tcmalloc具体策略
tcmalloc分配的内存主要来自两个地方:全局缓存堆和进程的私有缓存。对于一些小容量的内存申请是用进程的私有缓存,私有缓存不足的时候可以再从全局缓存申请一部分作为私有缓存。对于大容量的内存申请则需要从全局缓存中进行申请。而大小容量的边界就是32k。缓存的组织方式是一个单链表数组,数组的每个元素是一个单链表,链表中的每个元素具有相同的大小。
tcmalloc 整体结构
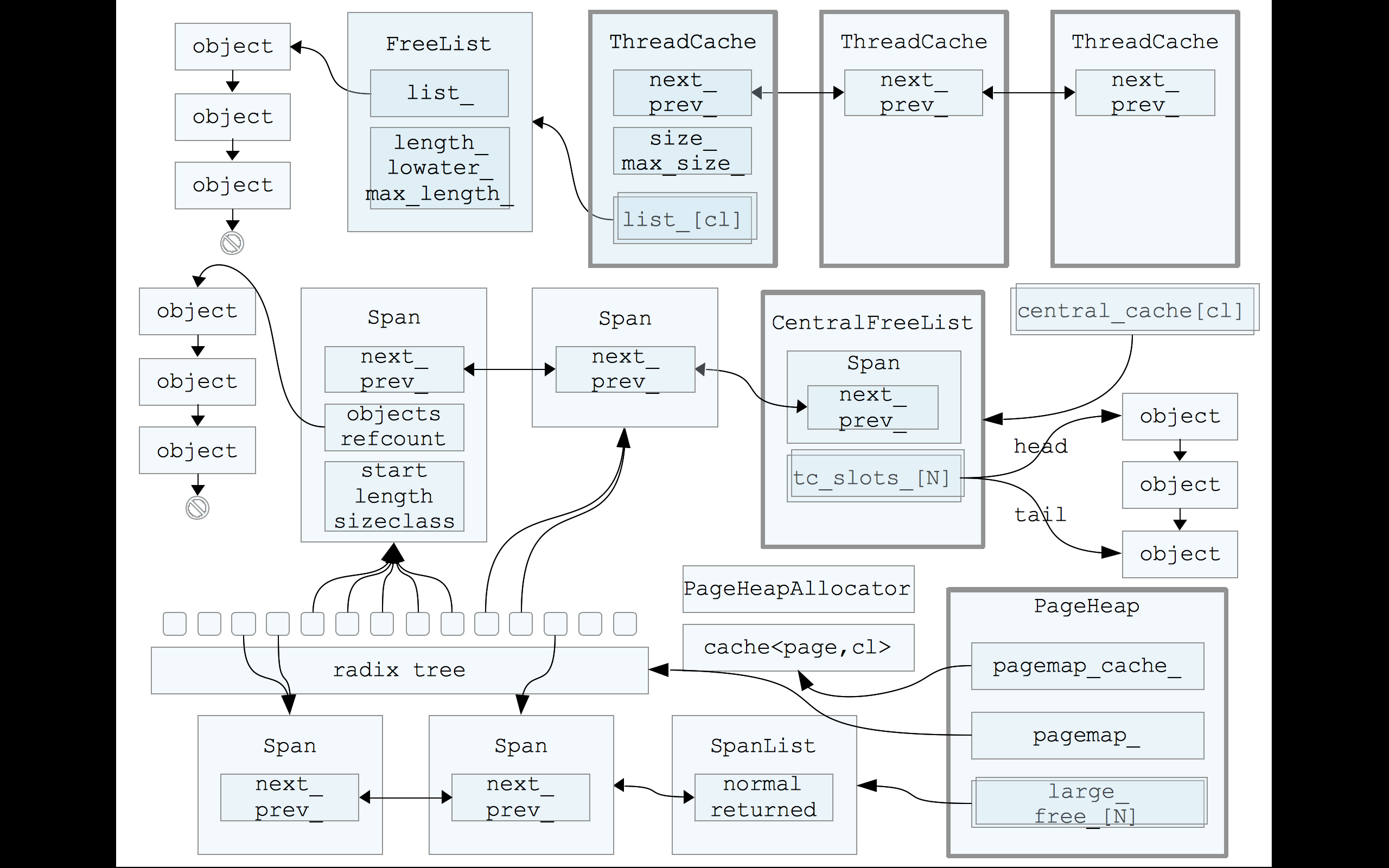
在tcmalloc内存管理的体系之中,一共有三个层次:ThreadCache、CentralCache、PageHeap,如上图所示。
分配内存和释放内存的时候都是按从前到后的顺序,在各个层次中去进行尝试。基本思想是:前面的层次分配内存失败,则从下一层分配一批补充上来;前面的层次释放了过多的内存,则回收一批到下一层次。
这几个层次从前到后,主要有这么几方面的变化:
- 线程私有性:ThreadCache,顾名思义,是每个线程一份的。理想情况下,每个线程的内存需求都在自己的ThreadCache里面完成,线程之间不需要竞争,非常高效。而CentralCache和PageHeap则是全局的;
- 内存分配粒度:在tcmalloc里面,有两种粒度的内存,object和span。span是连续page的内存,而object则是由span切成的小块。object的尺寸被预设了一些规格(class),比如16字节、32字节、等等,同一个span切出来的object都是相同的规格。object不大于256K,超大的内存将直接分配span来使用。ThreadCache和CentralCache都是管理object,而PageHeap管理的是span。
Small Object Allocation
小对象内存分配默认会分配86个不同大小的块,而这些块的大小并没有明确说明,需要查一下源码。每种大小的块的数组的长度都采用使用了才初始化,有点类似于lazy-initialize。

Big Object Allocation
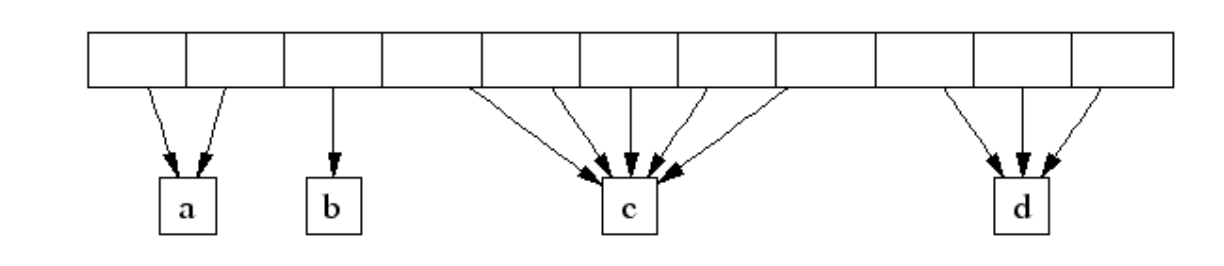
对于大于32k的内存申请,使用全局内存来分配。全局内存的组织也是单链表数组,数组长度为256,分别对用1 page大小, 2 page大小(1 page=4k).
Span
tcmalloc使用span来管理内存分页,一个span可以包含几个连续分页。span的状态只有未分配、作为大对象分配、作为小对象分配。
go的内存分配
go语言的内存分配并不是和tcmalloc一模一样。
- 局部缓存并不是分配给进程或者线程,而是分配给P(这个还需要说一下go的goroutine实现)
- go的GC是stop the world,并不是每个进程单独进行GC。
- span的管理更有效率